全球權(quán)威大模型盲測榜單公布,阿里千問3.6登頂中國最強編程模型
4月3日,全球知名大模型盲測榜單LMArena旗下聚焦AI編程能力的Code Arena公布新一期排名,阿里巴巴最新一代大語言模型Qwen 3.6-Plus登上全球榜單第二,超越OpenAI、Google、xAI等國際巨頭,成為該榜單上排名最高的中國大模型。
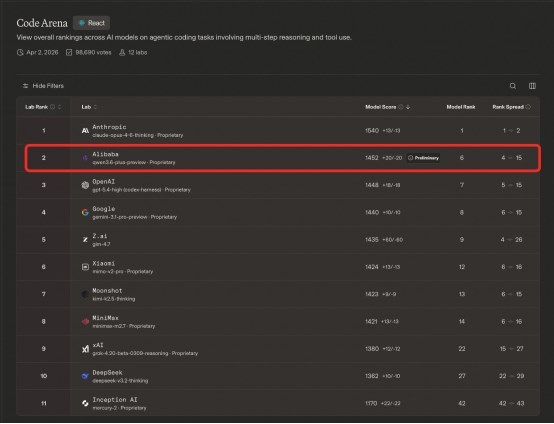
據(jù)了解,LMArena作為當(dāng)前AI領(lǐng)域最具公信力的大模型盲測平臺之一,采用真實用戶盲測、實時對抗排名的機制,因此也被視為是AI領(lǐng)域最公正權(quán)威的全球大模型性能榜單。隨著Agent時代到來,編程能力成為衡量模型綜合實力的關(guān)鍵,該榜單備受關(guān)注。本次Qwen3.6-Plus斬獲第二的React專項榜單是目前AI Coding領(lǐng)域最前沿、挑戰(zhàn)性最高的一個技術(shù)方向,旨在考察大模型在真實復(fù)雜Web開發(fā)場景下的自主編碼能力。與傳統(tǒng)的單一代碼補全測試不同,該榜單要求模型具備完整的工程思維和端到端開發(fā)能力,能夠在無人輔助的情況下獨立完成從項目初始化、代碼編寫到調(diào)試運行的全流程。
Qwen3.6-Plus是阿里于4月2日最新發(fā)布的新一代大語言模型,擁有原生多模態(tài)理解、推理能力,并在代碼生成與Agent能力上表現(xiàn)突出。在多項權(quán)威編程評測中,千問3.6均超越參數(shù)量是其兩倍乃至三倍的GLM-5、Kimi-K2.5等模型,以更少的參數(shù)實現(xiàn)了更強的性能,成為當(dāng)前國產(chǎn)模型中編程能力的標(biāo)桿。新模型發(fā)布首日便在全球開發(fā)者社區(qū)引發(fā)熱烈反響,次日即以1452分位列React榜單第二。
榜單數(shù)據(jù)顯示,千問3.6得分僅次于Anthropic旗下的Claude-Opus-4.6-Thinking(1540分),以4分優(yōu)勢領(lǐng)先OpenAI最新發(fā)布的GPT-5.0-High(1448分),并以12分差距超越Google的Gemini 3.1 Pro Preview(1440分)。這意味著,在最具挑戰(zhàn)性的AI Coding和Agent任務(wù)中,千問3.6展現(xiàn)出與全球頂級大模型比肩甚至更優(yōu)的代碼生成與工程化能力。此外,在全面評估AI編程能力的 Code Arena 榜單中,Qwen3.6-Plus同樣位居國產(chǎn)模型之首。憑借這一成績,阿里在全球 AI 實驗室排名中升至第四,僅次于 Anthropic、OpenAI 和 Google。
據(jù)悉,Qwen3.6-Plus是阿里千問3.6推出的第一款模型,后續(xù)千問3.6系列還將開源其他尺寸模型,性能更強的旗艦?zāi)P蚎wen3.6-Max也將于近期發(fā)布。
- 免責(zé)聲明:本文內(nèi)容與數(shù)據(jù)僅供參考,不構(gòu)成投資建議。據(jù)此操作,風(fēng)險自擔(dān)。
- 版權(quán)聲明:凡文章來源為“大眾證券報”的稿件,均為大眾證券報獨家版權(quán)所有,未經(jīng)許可不得轉(zhuǎn)載或鏡像;授權(quán)轉(zhuǎn)載必須注明來源為“大眾證券報”。
- 廣告/合作熱線:025-86256149
- 舉報/服務(wù)熱線:025-86256144
